
Alexa skills can be developed using Alexa Lambda functions or a REST API endpoint. Lambda function is Amazon’s implementation of serverless functions available in AWS. Amazon recommends using Lambda functions despite they are not easy to debug. While you can log to a CloudWatch log, you can’t hit a breakpoint and step into the code.
This makes live debugging of Alexa requests a very hard task. In this post, we will implement a custom skill for Amazon Alexa by using TypeScript, npm and AWS Lambda Functions. This skill is basically a Hello World example. With this post you will be able to create a custom skill for Amazon Alexa, implement functionality by using TypeScript and start your custom skill both from your local computer and from AWS. This post contains materials from different resources that can be seen on Resources section.
Here you have the technologies used in this project
- Amazon Developer Account – How to get it
- AWS Account – Sign up here for free
- ASK CLI – Install and configure ASK CLI
- Node.js v10.x
- TypeScript (Version >3.0.0)
- Visual Studio Code
- npm Package Manager
- Alexa ASK for Node.js (Version >2.7.0)
- ngrok
The Alexa Skills Kit Command Line Interface (ASK CLI) is a tool for you to manage your Alexa skills and related resources, such as AWS Lambda functions. With ASK CLI, you have access to the Skill Management API, which allows you to manage Alexa skills programmatically from the command line. We will use this powerful tool to create, build, deploy and manage our Hello World Skill but now, with TypeScript. Let’s start!
If you want how to create your Skill with the ASK CLI, please follow the first step explained in my Node.js Skill sample
Once we have created the Skill in Node.js, we have to rewrite or ‘transpile’ our code to TypeScript. I have made that work for you. Let’s take a look on it!
These are the main files of the project:
├───.ask/
│ config
├───.vscode/
│ launch.json
├───hooks/
├───lambda/
│ └───custom/
│ │ └───build/
│ │ local-debugger.js
│ │ package.json
│ │ tsconfig.json
│ │ tslint.json
│ └───src/
│ ├───index.ts
│ ├───errors/
│ ├───intents/
│ ├───interceptors/
│ └───utilities/
│
├───models/
└───skill.json
- .ask: folder which contains the ASK CLI’s config file. This config files will remain empty until we execute the command
ask deploy .vscode/launch.json: Launch preferences to run locally your Skill for local testing. This setting launchlambda/custom/src/local-debugger.js. This script runs a server on http://localhost:3001 for debug the Skill. It is not traspilled to TypeScript because it is not a part from our lambda. It is a local tool.- hooks: A folder that contains the hook scripts. Amazon provides two hooks, post_new_hook and pre_deploy_hook
post_new_hook: executed after the Skill creation. Inn Node.js runsnpm installin each sourceDir inskill.jsonpre_deploy_hook: executed before the Skill deployment. In Node.js runsnpm installin each sourceDir inskill.jsonas well
- lambda/custom/src: A folder that contains the source code for the skill’s AWS Lambda function:
index.ts: the lambda main entry pointpackage.json: this file is core to the Node.js ecosystem and is a basic part of understanding and working with Node.js, npm, and even modern TypeScripttsconfig.json: configuration file that we are going to use for compiling our TypeScript codetslint.json: configuration file used bygts(Google TypeScript Style) to check the style of our TypeScript codelocal-debugger.js: used for debug our skill locallyerrors: folder that contains all error handlersintents: this one contains all the intent handlersinterceptors: interceptors’ folder with the i18n initializationutilities: this folder contains the i18n strings, helper functions, constants and TypeScript interfacesbuild: the output folder after compiling the TypeScript code
- models – A folder that contains interaction models for the skill. Each interaction model is defined in a JSON file named according to the locale. For example, es-ES.json
skill.json– The skill manifest. One of the most important files in our project
The ASK SDK for Node.js makes it easier for you to build highly engaging skills by allowing you to spend more time implementing features and less time writing boilerplate code.
We are going to use this SDK but now in TypeScript!
You can find documentation, samples and helpful links in their official GitHub repository
The main TypeScript file in our lambda project is index.ts located in lambda/custom/src folder. This file contains all handlers, interceptors and exports the Skill handler in exports.handler.
The exports.handler function is executed every time AWS Lambda is initiated for this particular function.
In theory, an AWS Lambda function is just a single function. This means that we need to define dispatching logic so a single function request can route to appropriate code, hence the handlers.
import * as Alexa from 'ask-sdk-core';
import { Launch } from './intents/Launch';
import { Help } from './intents/Help';
import { Stop } from './intents/Stop';
import { Reflector } from './intents/Reflector';
import { Fallback } from './intents/Fallback';
import { HelloWorld } from './intents/HelloWorld';
import { ErrorProcessor } from './errors/ErrorProcessor';
import { SessionEnded } from './intents/SessionEnded';
import { LocalizationRequestInterceptor } from './interceptors/LocalizationRequestInterceptor';
export const handler = Alexa.SkillBuilders.custom()
.addRequestHandlers(
// Default intents
Launch,
HelloWorld,
Help,
Stop,
SessionEnded,
Reflector,
Fallback
)
.addErrorHandlers(ErrorProcessor)
.addRequestInterceptors(LocalizationRequestInterceptor)
.lambda();It is important to take a look into the Launch.ts, imported as Launch above, which is the LaunchRequestHandler handler located in the intents folder as an example of Alexa Skill handler written in TypeScript:
import { RequestHandler, HandlerInput } from 'ask-sdk-core';
import { RequestTypes, Strings } from '../utilities/constants';
import { IsType } from '../utilities/helpers';
import i18n from 'i18next';
export const Launch: RequestHandler = {
canHandle(handlerInput: HandlerInput) {
return IsType(handlerInput, RequestTypes.Launch);
},
handle(handlerInput: HandlerInput) {
const speechText = i18n.t(Strings.WELCOME_MSG);
return handlerInput.responseBuilder
.speak(speechText)
.reprompt(speechText)
.withSimpleCard(i18n.t(Strings.SKILL_NAME), speechText)
.getResponse();
},
};Inside package.json, we will almost always find metadata specific to the project.
This metadata helps identify the project and acts as a baseline for users and contributors to get information about the project.
Here is how this file looks like:
{
"name": "alexa-typescript-lambda-helloworld",
"version": "1.0.0",
"description": "Alexa HelloWorld example with TypeScript",
"main": "index.js",
"scripts": {
"clean": "rimraf build",
"compile": "tsc --build tsconfig.json --pretty",
"build-final": "cpy package.json build && cd build/ && npm install --production",
"test": "echo \"No test specified yet\" && exit 0",
"lint-check": "gts check",
"lint-clean": "gts clean",
"lint-fix": "gts fix",
"build": "npm run clean && npm run test && npm run lint-check && npm run compile && npm run build-final"
},
"repository": {
"type": "git",
"url": "https://github.com/xavidop/alexa-typescript-lambda-helloworld.git"
},
"author": "Xavier Portilla Edo",
"license": "Apache-2.0",
"dependencies": {
"ask-sdk-core": "^2.7.0",
"ask-sdk-model": "^1.19.0",
"aws-sdk": "^2.326.0",
"i18next": "^15.0.5",
"i18next-sprintf-postprocessor": "^0.2.2"
},
"devDependencies": {
"@types/node": "^10.10.0",
"@types/i18next-sprintf-postprocessor": "^0.2.0",
"typescript": "^3.0.2",
"cpy-cli": "^3.1.0",
"rimraf": "^3.0.0",
"ts-node": "^7.0.1",
"gts": "^1.1.2"
}
}
With TypeScript we have to compile our code to generate the JavaScript code. For build our Skill, we can run the following command:
npm run build
This command will execute these actions:
- Remove the
buildfolder located inlambda/customwith the commandrimraf build. This folder contains the output of compiling the TypeScript code - Check the style of our TypeScript code with the command
gts checkusing the filetslint.json - Compiles the TypeScript and generates the JavaScript code in the output folder
lambda/custom/buildusing the commandtsc --build tsconfig.json --pretty - Copy the
package.jsonto thebuildfolder because is needed to generate the final lambda code - Finally, it will run the
npm install --productioninbuildfolder to get the final lambda code that we are going to upload to AWS with the ASK CLI.
As you can see, this process in a TypeScript environment is more complex than in JavaScript one.
The launch.json file in .vscode folder has the configuration for Visual Studio Code which allow us to run our lambda locally:
{
"version": "0.2.0",
"configurations": [
{
"type": "node",
"request": "launch",
"name": "Launch Skill",
// Specify path to the downloaded local adapter(for nodejs) file
"program": "${workspaceRoot}/lambda/custom/local-debugger.js",
"args": [
// port number on your local host where the alexa requests will be routed to
"--portNumber", "3001",
// name of your nodejs main skill file
"--skillEntryFile", "${workspaceRoot}/lambda/custom/build/index.js",
// name of your lambda handler
"--lambdaHandler", "handler"
]
}
]
}
This configuration file will execute the following command:
node --inspect-brk=28448 lambda\custom\local-debugger.js --portNumber 3001 --skillEntryFile lambda/custom/build/index.js --lambdaHandler handler
This configuration uses the local-debugger.js file which runs a TCP server listening on http://localhost:3001
For a new incoming skill request a new socket connection is established. From the data received on the socket the request body is extracted, parsed into JSON and passed to the skill invoker’s lambda handler. The response from the lambda handler is parsed as a HTTP 200 message format as specified here The response is written onto the socket connection and returned.
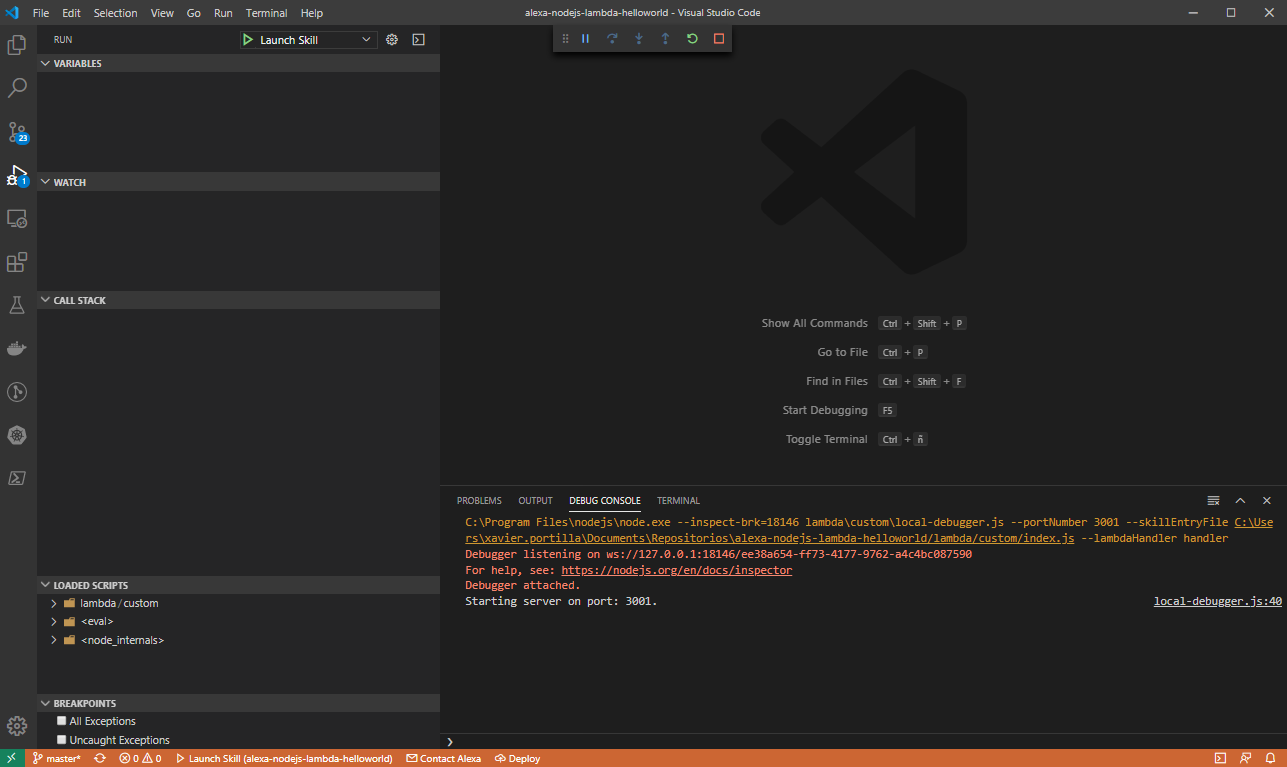
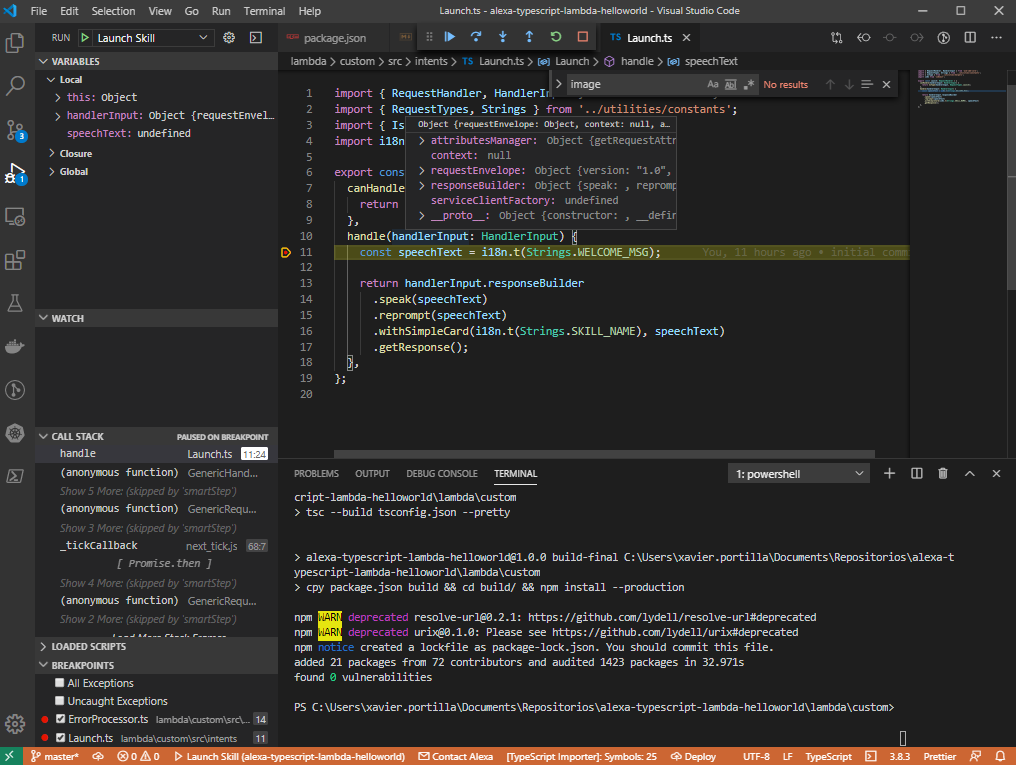
After configuring our launch.json file and understanding how the local debugger works, it is time to click on the play button:

After executing it, you can send Alexa POST requests to http://localhost:3001.
Following the steps before, now you can set up breakpoints wherever you want inside all TypeScript files in order to debug your skill:

I’m sure you already know the famous tool call Postman. REST APIs have become the new standard in providing a public and secure interface for your service. Though REST has become ubiquitous, it’s not always easy to test. Postman, makes it easier to test and manage HTTP REST APIs. Postman gives us multiple features to import, test and share APIs, which will help you and your team be more productive in the long run.
After run your application you will have an endpoint available at http://localhost:3001. With Postman you can emulate any Alexa Request.
For example, you can test a LaunchRequest:
{
"version": "1.0",
"session": {
"new": true,
"sessionId": "amzn1.echo-api.session.[unique-value-here]",
"application": {
"applicationId": "amzn1.ask.skill.[unique-value-here]"
},
"user": {
"userId": "amzn1.ask.account.[unique-value-here]"
},
"attributes": {}
},
"context": {
"AudioPlayer": {
"playerActivity": "IDLE"
},
"System": {
"application": {
"applicationId": "amzn1.ask.skill.[unique-value-here]"
},
"user": {
"userId": "amzn1.ask.account.[unique-value-here]"
},
"device": {
"supportedInterfaces": {
"AudioPlayer": {}
}
}
}
},
"request": {
"type": "LaunchRequest",
"requestId": "amzn1.echo-api.request.[unique-value-here]",
"timestamp": "2020-03-22T17:24:44Z",
"locale": "en-US"
}
}
With the code ready to go, we need to deploy it on AWS Lambda so it can be connected to Alexa.
Before deploy the Alexa Skill, we can show the config file in .ask folder it is empty:
{
"deploy_settings": {
"default": {
"skill_id": "",
"was_cloned": false,
"merge": {}
}
}
}
Deploy Alexa Skill with ASK CLI:
ask deployAs the official documentation says:
When the local skill project has never been deployed, ASK CLI creates a new skill in the development stage for your account, then deploys the skill project. If applicable, ASK CLI creates one or more new AWS Lambda functions in your AWS account and uploads the Lambda function code. Specifically, ASK CLI does the following:
- Looks in your skill project’s config file (in the .ask folder, which is in the skill project folder) for an existing skill ID. If the config file does not contain a skill ID, ASK CLI creates a new skill using the skill manifest in the skill project’s skill.json file, then adds the skill ID to the skill project’s config file.
- Looks in your skill project’s manifest (skill.json file) for the skill’s published locales. These are listed in the manifest.publishingInformation.locales object. For each locale, ASK CLI looks in the skill project’s models folder for a corresponding model file (for example, es-ES.json), then uploads the model to your skill. ASK CLI waits for the uploaded models to build, then adds each model’s eTag to the skill project’s config file.
- Looks in your skill project’s manifest (skill.json file) for AWS Lambda endpoints. These are listed in the manifest.apis..endpoint or manifest.apis..regions..endpoint objects (for example, manifest.apis.custom.endpoint or manifest.apis.smartHome.regions.NA.endpoint). Each endpoint object contains a sourceDir value, and optionally a uri value. ASK CLI upload the contents of the sourceDir folder to the corresponding AWS Lambda function and names the Lambda function the same as the uri value. For more details about how ASK CLI performs uploads to Lambda, see AWS Lambda deployment details.
- Looks in your skill project folder for in-skill products, and if it finds any, uploads them to your skill. For more information about in-skill products, see the In-Skill Purchasing Overview.
After the execution of the above command, we will have the config file properly filled:
{
"deploy_settings": {
"default": {
"skill_id": "amzn1.ask.skill.945814d5-9b30-4ee7-ade6-f5ef017a1c17",
"was_cloned": false,
"merge": {},
"resources": {
"manifest": {
"eTag": "ea0bd8c176a560f95a64fe7a1ba99315"
},
"interactionModel": {
"es-ES": {
"eTag": "4a185611054c722446536c5659593aa3"
}
},
"lambda": [
{
"alexaUsage": [
"custom/default"
],
"arn": "arn:aws:lambda:us-east-1:141568529918:function:ask-custom-alexa-typescript-lambda-helloworld-default",
"awsRegion": "us-east-1",
"codeUri": "lambda/custom/build",
"functionName": "ask-custom-alexa-typescript-lambda-helloworld-default",
"handler": "index.handler",
"revisionId": "477bcf34-937d-4fa4-8588-8db8ec1e7213",
"runtime": "nodejs10.x"
}
]
}
}
}
}
NOTE: after rewriting our code to TypeScript we need to change the codeUri from lambda/custom to lambda/custom/build because of our code compiled from TypeScript to JavaScript goes to the output folder build.
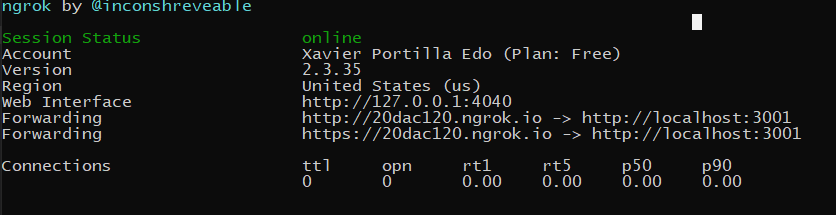
ngrok is a very cool, lightweight tool that creates a secure tunnel on your local machine along with a public URL you can use for browsing your local site or APIs.
When ngrok is running, it listens on the same port that you’re local web server is running on and proxies external requests to your local machine
From there, it’s a simple step to get it to listen to your web server. Say you’re running your local web server on port 3001. In terminal, you’d type in: ngrok http 3001. This starts ngrok listening on port 3001 and creates the secure tunnel:

So now you have to go to Alexa Developer console, go to your skill > endpoints > https, add the https url generated above . Eg: https://20dac120.ngrok.io.
Select the My development endpoint is a sub-domain…. option from the dropdown and click save endpoint at the top of the page.
Go to Test tab in the Alexa Developer Console and launch your skill.
The Alexa Developer Console will send a HTTPS request to the ngrok endpoint (https://20dac120.ngrok.io) which will route it to your skill running on Web API server at http://localhost:3001.
- Official Alexa Skills Kit Node.js SDK – The Official Node.js SDK Documentation
- Official Alexa Skills Kit Documentation – Official Alexa Skills Kit Documentation
This was a basic tutorial to learn Alexa Skills using Node.js and TypeScript. As you have seen in this example, the Alexa Skill Kit for Node.js and the Alexa Tools like ASK CLI can help us a lot and also they give us the possibility to create skills in TypeScript in an easy way. I hope this example project is useful to you.
That’s all folks!
Happy coding!
 https://github.com/xavidop/alexa-typescript-lambda-helloworld
https://github.com/xavidop/alexa-typescript-lambda-helloworld




















{kind=link}